-
- Downloads
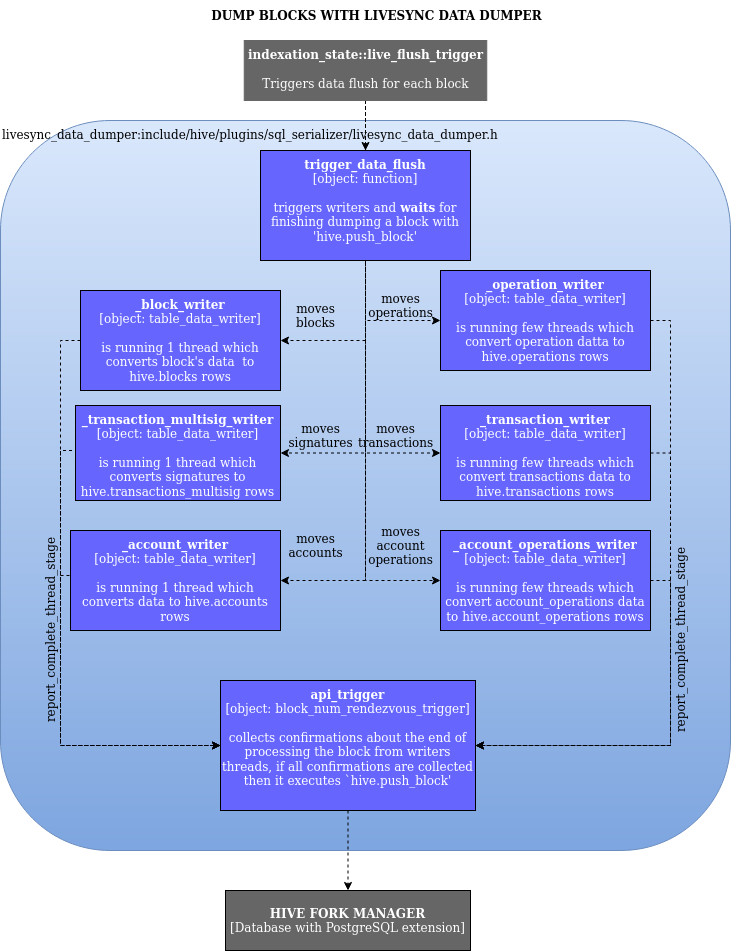
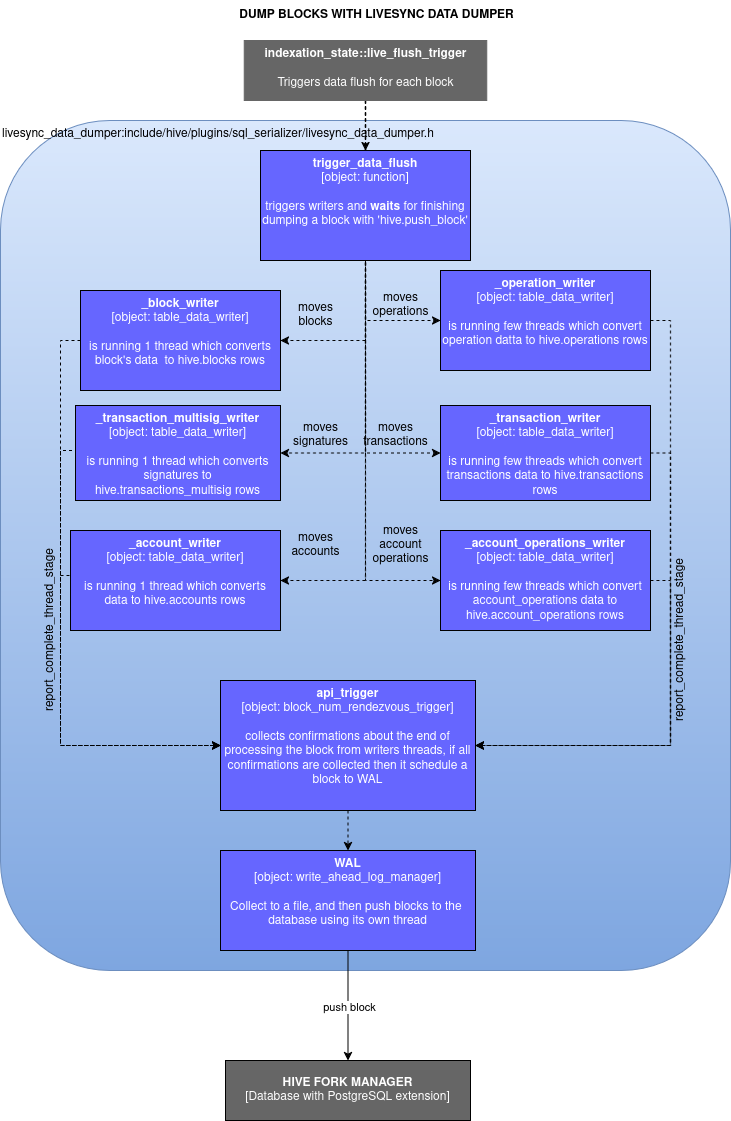
update doc: WAL
parent
933662a0
No related branches found
No related tags found
Pipeline #118763 canceled
Stage: build_and_test_phase_1
Stage: build_and_test_phase_2
Stage: cleanup
{kind=link}
{kind=link}
| W: | H:
| W: | H:
| W: | H:
| W: | H: